

This post describes how ML infrastructure has evolved over the last decade from the point of view of the ML practitioner, i.e., somebody who builds and trains ML models.
Single-Box and In-Memory
This is where it all started. This was when scikit-learn was the main ML framework. The data volume was small enough to fit into the main memory of a single machine. ML practitioners usually copied their entire dataset onto the HDD of a machine. Their models were also small enough to co-exist with the data in the main memory of this machine. They wrote their trainer program, usually in Python, s.t. it loaded the entire dataset into the memory, loaded the Python package containing the model, and then ran the training to produce the trained parameters, usually in a matter of hours. This paradigm was characterized by -
- Data volume: small
- Model size: small
- Model complexity: low
Single-Box but Data not In-Memory
Frameworks like PyTorch and Tensorflow-2 are the main tools of the trade. Data no longer fits into the main memory, though it probably fits into the SSD of a single machine. The model size is small enough to fit into the memory, but its complexity probably justifies the use of a GPU. The trainer code now loads small batches of data into the memory and learns from it incrementally. The training still finishes in a "reasonable" amount of time, but it is more in terms of days than hours. This paradigm is characterized by -
- Data volume: medium
- Model size: small
- Model complexity: medium

Distributed Data Parallel (DDP)
Now the data volume and model complexity both have grown to the point where incrementally learning from a batch of data just takes too long, even with a GPU. The main idea in DDP is to break data into multiple partitions and have a copy of the model learn from each partition. Model replicas synchronize their parameters every so often using some variation of the allreduce function. While most modern frameworks handle the distributed training part well enough, ML practitioners still have to do the heavy lifting in terms of provisioning the underlying hardware, and partitioning and making the data available to the trainer replicas. Depending on the data volume this can involve building a Big Data system in and of itself. This space is characterized by -
- Data volume: large
- Model size: medium
- Model complexity: large

Automated DDP
A few ML practitioners I know are trying to automate the hardware provisioning and data partition steps mentioned above. This is hard because it is not an exact science, though generally speaking the number of partitions and replicas tend to eventually follow the law of diminishing returns. Most of the approaches I have seen model this as a constraint optimization problem and are able to use existing solutions from that domain. I believe that development in this space is crucial to make DDP more mainstream.
Model Parallelism (MP)
By now the model size has outgrown the memory of a single machine. The main idea in MP is to break the compute graph of the model into smaller graphs and place each shard of sub-graph onto a separate GPU. For smaller models, multiple GPUs on a single machine will suffice, but for larger models like the GPT-2, multiple multi-GPU machines are needed. Data pipelining goes hand-in-hand with MP to ensure that downstream shards are not blocked by upstream shards. Frameworks like PyTorch provide good primitives for data pipelining and multi-machine MP, but here again ML practitioners have to do a lot more software engineering, including deciding how to manually shard the compute graph. This space is characterized by -
- Data volume: large
- Model size: large
- Model complexity: large
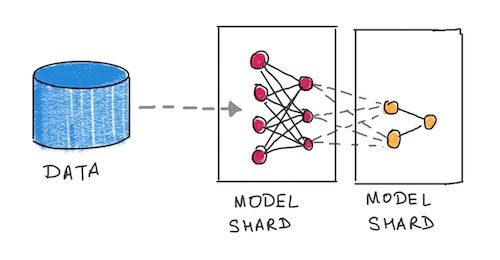
Automated MP
This is an active area of research where folks are trying to come up with ways to automatically shard the compute graph. This is mostly being modeled as a graph partitioning problem and approaches similar to constrained optimizations are being applied to solve this as well.
Conclusion
Here is my totally unscientific conclusion based on my read of the industry. Most small and medium sized businesses do not need anything more sophisticated than the single-box ML paradigm. Academic research along with some data intensive businesss, e.g., those dealing with automated sensor data, simulated data, etc. are starting to feel the limitations of the single-box paradigm and are reaching for DDP. Automated DDP is crucial in making it easily accessible to this group. Industrial research and businesses with extreme scale, typically FAANG companies, are using MP today.
Splash Photo by Cenk Batuhan Özaltun on Unsplash